快科技于今日(12 月 12 日)传来消息,谷歌正式对外发布了专为新智能体时代打造的下一代模型——Gemini 2.0。

这一模型堪称谷歌截至目前功能最为强大的 AI 模型,它具备更卓越的性能、更丰富的多模态表现(例如原生的图像和音频输出功能)以及全新的原生工具应用。
在关键基准测试里,Gemini 2.0 相较于前代产品 Gemini 1.5 Pro 实现了性能的显著提升,运行速度甚至达到了后者的两倍之多。
它支持图像、视频和音频等多模态的输入与输出,像与文本相混合的原生文生图功能,以及可自定义的文本转语音(TTS)多语言音频内容。
此外,Gemini 2.0 还支持原生调用工具,比如 Google 搜索、代码执行以及第三方用户定义函数等,为用户提供了更加便捷且强大的功能体验。
从技术层面来看,Gemini 2.0 采用了最新的机器学习和深度学习算法,优化了神经网络的结构,提升了其运行效率,尤其在自然语言处理(NLP)领域表现突出。
这些技术创新让 Gemini 2.0 能够更精准地理解和生成自然语言,极大地增强了人机交互的智能性。
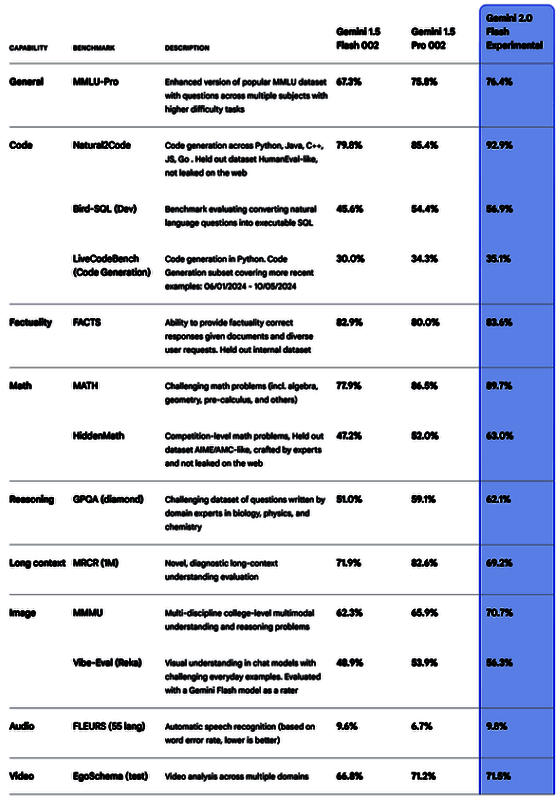
从即日起,开发人员就可以在 AI Studio 和 Vertex AI 中对 Gemini 2.0 Flash 实验版本进行试用,而且该版本也已经在网页版中为 Gemini Advanced 开放试用,移动版后续也会推出。
为了助力开发者构建动态且交互式的应用程序,谷歌还发布了全新的 Multimodal Live API,它具备实时音频、视频流输入以及使用多个组合工具的能力。
到明年年初,Gemini 2.0 还会在更多 Google 产品中得到应用。